SLA-Driven Profiling with DynamoGraphDeploymentRequest — NVIDIA Dynamo Documentation
Title: SLA-Driven Profiling with DynamoGraphDeploymentRequest — NVIDIA Dynamo Documentation
URL Source: https://docs.nvidia.com/dynamo/latest/benchmarks/sla_driven_profiling.html
Published Time: Fri, 07 Nov 2025 17:51:32 GMT
Markdown Content: SLA-Driven Profiling with DynamoGraphDeploymentRequest#
Tip
New to DGDR and SLA-Driven Profiling? Start with the SLA-Driven Profiling and Planner Deployment Quick Start Guide for step-by-step instructions. This document provides deeper technical details about the profiling process.
Overview#
Dynamo provides automated SLA-driven profiling through DynamoGraphDeploymentRequests (DGDR). Instead of manually running profiling scripts, you declare your performance requirements and let the Dynamo Operator handle profiling and deployment automatically.
Key Benefits:
-
Declarative: Specify SLAs, not implementation details
-
Automated: No manual job setup or result processing
-
Integrated: Seamlessly works with Dynamo Operator
-
Production-Ready: Generates optimized configurations with SLA planner
This document covers:
-
Technical details of online vs offline profiling
-
Profiling process internals (GPU usage, measurements, interpolation)
-
Direct script usage for advanced scenarios
-
Comprehensive troubleshooting
Support Matrix#
| Backend | Dense Models (P:TP, D:TP) | MoE Models (P:TEP, D:DEP) |
|---|---|---|
| vLLM | ✅ | 🚧 |
| SGLang | ✅ | ✅ |
| TensorRT-LLM | ✅ | 🚧 |
Note
-
We only support multi-node engines for MoE models.
-
For MoE models, we currently only support deepseek-style MLA+MoE models. For other MoE models like GQA+MoE, please use the dense mode (sweep over TP sizes) instead.
-
Exact model x parallelization mapping support is dependent on the backend. The profiler does not guarantee that the recommended P/D engine configuration is supported and bug-free by the backend.
Using DGDR for Profiling (Recommended)#
The recommended way to profile models is through DGDRs. Sample configurations are provided in deploy/:
Available Samples:
-
profile_sla_dgdr.yaml: Standard profiling with AIPerf on real engines -
profile_sla_aic_dgdr.yaml: Fast profiling with AI Configurator simulation -
profile_sla_moe_dgdr.yaml: MoE model profiling
The Dynamo Operator automatically:
-
Discovers GPU resources
-
Runs profiling (AIPerf on real engines or AI Configurator simulation)
-
Generates optimal DGD configuration with SLA planner
-
Deploys the DGD to your cluster
See the Quick Start Guide for prerequisites and detailed instructions.
Profiling Method#
-
GPU Discovery: Detects available GPUs and their specifications
-
Identify Sweep Ranges: Automatically determine minimum and maximum number of GPUs per engine. Minimum is determined by the model size and GPU VRAM. Maximum is set to one node for dense model and 4 nodes for MoE models.
-
Parallelization Mapping Sweep: Use the input ISL and OSL, test the performance of the engines with different parallelization mappings. For dense models, we test different TP sizes for both prefill and decode. For MoE models, we test different TEP sizes for prefill and DEP sizes for decode.
* **Prefill**: For prefill, since there is no in-flight batching (assume isl is long enough to saturate the GPU), we directly measure the TTFT for a request with given isl without kv-reusing. For example, the below plot shows the prefill parallelization mapping sweep results for H100 for deepseek-ai/DeepSeek-R1-Distill-Llama-8B. 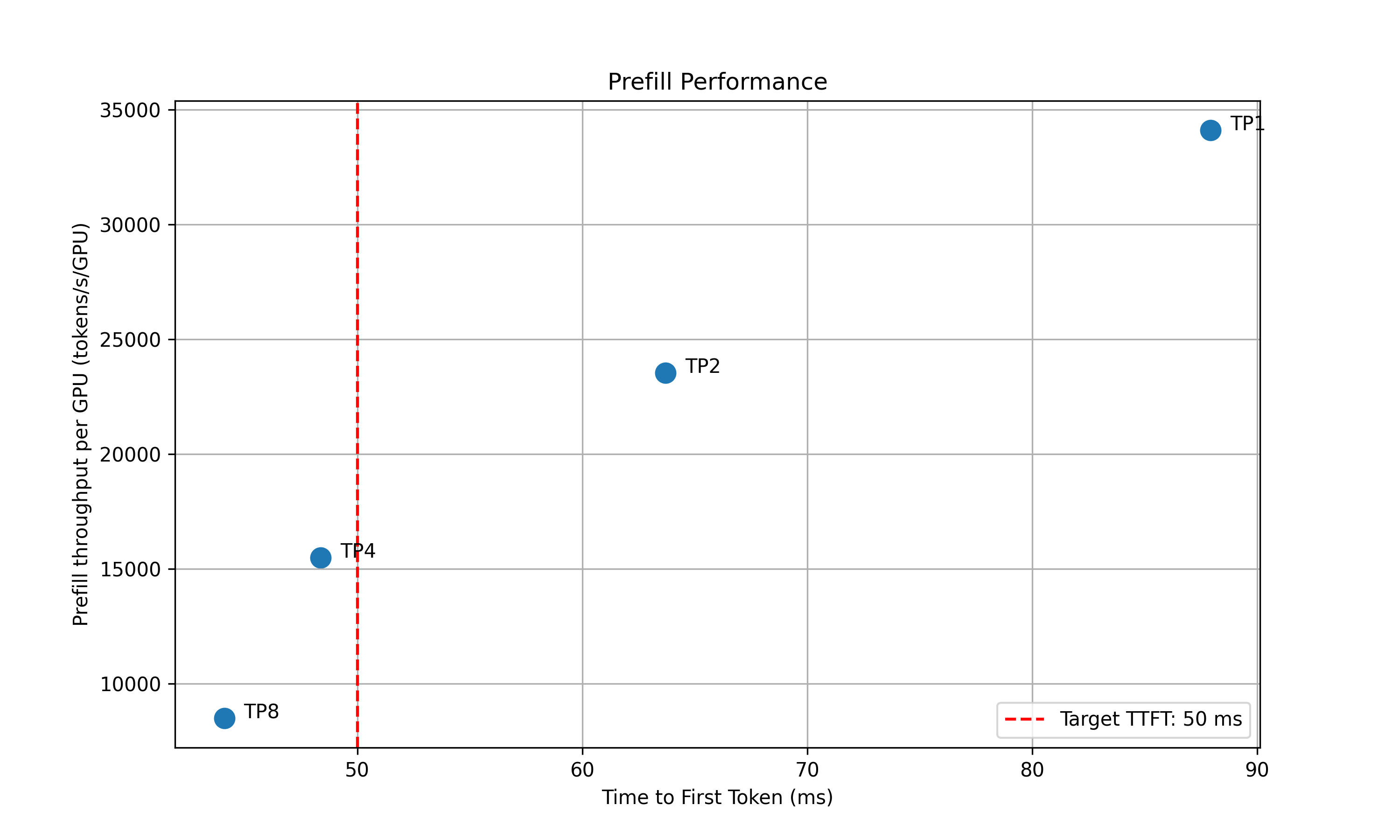
* **Decode**: Since the ITL (or iteration time) is relevant with how many requests are in-flight, we measure the ITL under different number of in-flight requests. The range of the number of in-flight requests is from 1 to the maximum number of requests that the kv cache of the engine can hold. To measure the ITL without being affected by piggy-backed prefill requests, the script will enable kv-reuse and warm up the engine by issuing the same prompts before measuring the ITL. Since the kv cache is sufficient for all the requests, it can hold the kv cache of the pre-computed prompts and skip the prefill phase when measuring the ITL. However, for MoE models, this is not guaranteed because the kv cache in different attention DP ranks is different. We are working on framework-side change to fix this issue. For example, the below plot shows the decode parallelization mapping sweep results for H100 for deepseek-ai/DeepSeek-R1-Distill-Llama-8B. 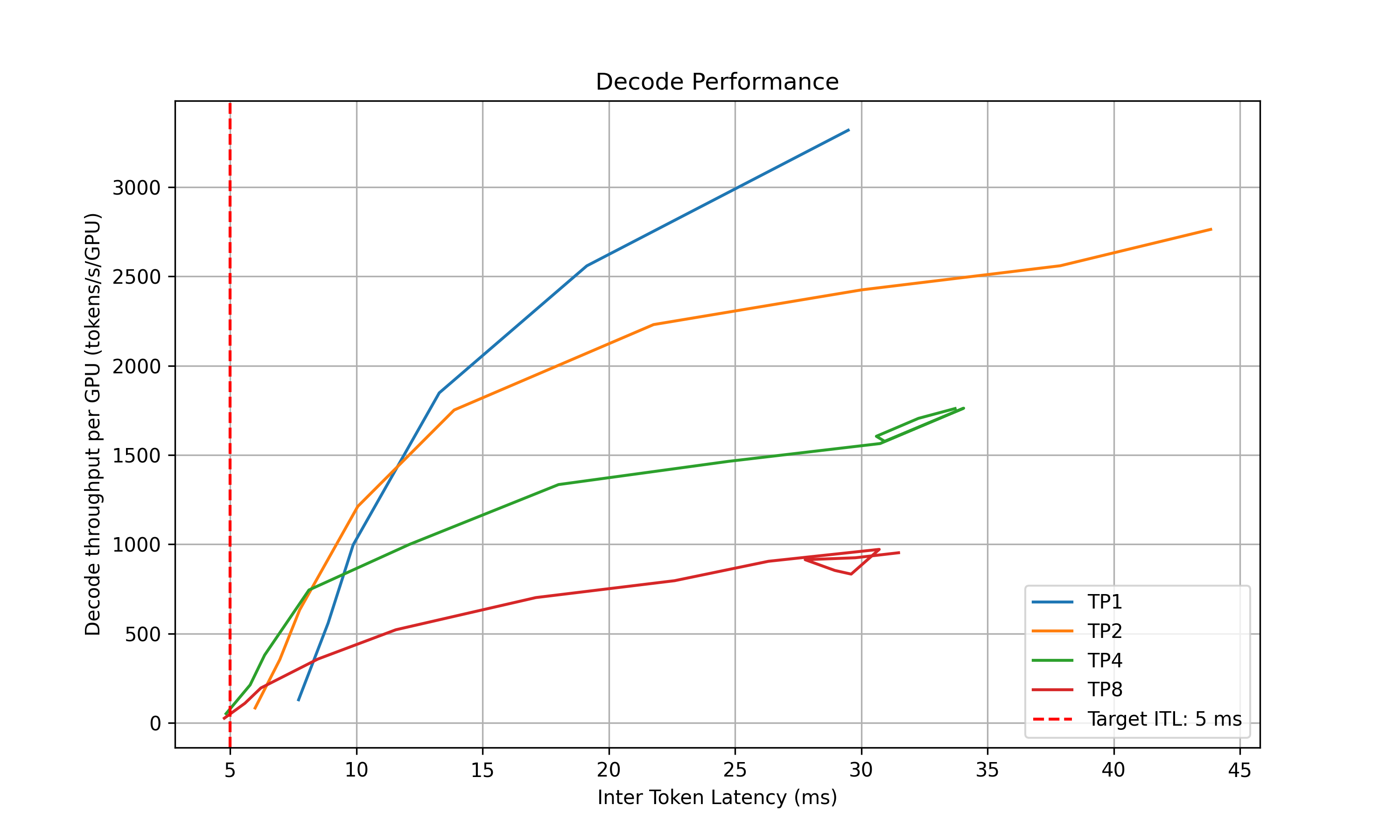
4. Recommendation: Selects optimal parallelization mapping for prefill and decode that achieves the highest per GPU throughput while adhering the SLA on TTFT and ITL. Specifically, the profiler will choose the point (or a point on the curve for decode) that is left to the vertical red dashed line that represents the SLAs while has the highest y coordinate (throughput per GPU).
- In-Depth Profiling on the Recommended P/D Engine: After finding the best TP size for prefill and decode, the script will then interpolate the TTFT with ISL and ITL with active KV cache and decode context length. This is to provide a more accurate estimation of the performance when ISL and OSL changes and will be used in the sla-planner.
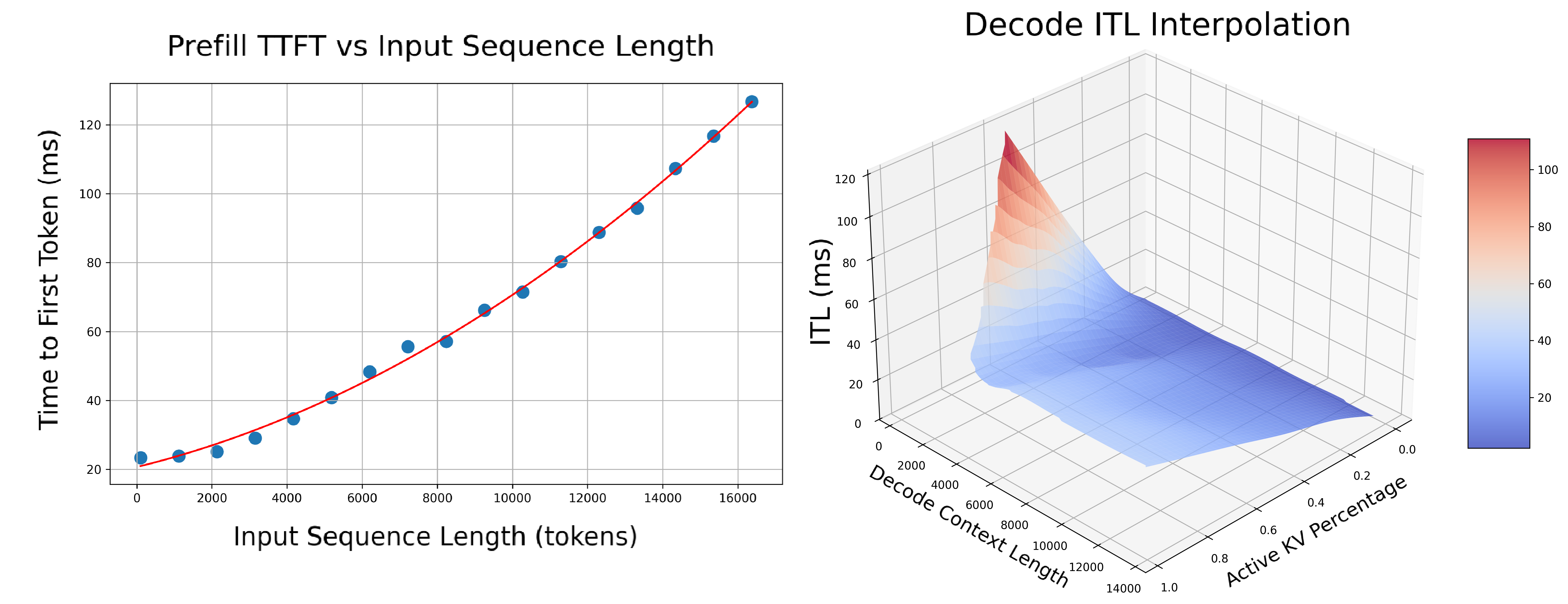
* **Prefill**: Measures TTFT and throughput per GPU across different input lengths with batch size=1.
* **Decode**: Measures ITL and throughput per GPU under various KV cache loads and decode context lengths. The active kv usage determines the complexity of the memory-bounded attention kernel while the active kv usage divided the average context length determines the complexity of the computation bound MLP kernel. For example, the below figure shows the ITL of DS-Distilled Llama 8b model on H100 TP4. The ITL grows near-linearly with active kv usage under a fixed context length. And the slope increases as the context length decreases.
To run the parallelization mapping sweep and the in-depth profiling on the recommended P/D engine, the profiler need to know the engine’s forward pass time with different loads. There are two ways to achieve this: run AIPerf on real engines or use AI Configurator to run simulations.
AIPerf on Real Engines#
Profiles your model by creating real test deployments in Kubernetes and measuring their performance.
Characteristics:
-
Duration: 2-4 hours
-
Accuracy: Highest (real measurements)
-
GPU Requirements: Full access to test different parallelization mappings
-
Backends: vLLM, SGLang, TensorRT-LLM
DGDR Configuration:
profilingConfig: config: sweep: use_ai_configurator: false # Default
AI Configurator Simulation#
Uses performance simulation to rapidly estimate optimal configurations without running real deployments.
Characteristics:
-
Duration: 20-30 seconds
-
Accuracy: Estimated (may have errors for unusual configurations)
-
GPU Requirements: None
-
Backends: TensorRT-LLM only (vLLM/SGLang coming soon)
DGDR Configuration:
profilingConfig: config: sweep: use_ai_configurator: true aic: system: h200_sxm # GPU system type model_name: QWEN3_32B # AIC model identifier backend_version: "0.20.0"
Supported Configurations:
For the current list of supported models, systems, and backend versions, see the AI Configurator documentation.
To check from the command line: aiconfigurator cli --help
Currently supports:
-
Backends: TensorRT-LLM (versions 0.20.0, 1.0.0rc3, 1.0.0rc6)
-
Systems: H100 SXM, H200 SXM, B200 SXM, GB200 SXM, A100 SXM
-
Models: Wide range including GPT, Llama, Mixtral, DeepSeek, Qwen, and more
Output Format#
After profiling, the DGDR status contains:
-
Recommended Configuration: Optimal TP for prefill and decode
-
Performance Data: Interpolation models for SLA planner
-
Generated DGD: Complete deployment manifest
Example Recommendations:
Suggested prefill TP:4 (TTFT 48.37 ms, throughput 15505.23 tokens/s/GPU) Suggested decode TP:4 (ITL 4.83 ms, throughput 51.22 tokens/s/GPU)
Output Performance Plots#
The profiler will generate the following plots to better visualize the performance data:
Parallelization Mapping Sweep Plots:
-
prefill_performance.png: TTFT vs Parallelization Mapping size -
decode_performance.png: ITL vs Parallelization Mapping size and in-flight requests
Note these two plots are based on the input ISL and OSL.
In-Depth Profiling for the Recommended P/D Engine Plots:
-
selected_prefill_interpolation/prefill_ttft_interpolation.png: TTFT vs ISL for the recommended prefill engine -
selected_prefill_interpolation/prefill_throughput_interpolation.png: Throughput vs ISL for the recommended prefill engine -
selected_decode_interpolation/decode_itl_interplation.png: ITL vs KV usage and context length for the recommended decode engine -
selected_decode_interpolation/decode_throughput_interpolation.png: Throughput vs KV usage and context length for the recommended decode engine
Output Interpolation Data#
The profiler generates .npz files to store the performance data for the recommended P/D engine:
Prefill Interpolation (selected_prefill_interpolation/raw_data.npz):
-
prefill_isl: 1D array of input sequence lengths tested -
prefill_ttft: 1D array of TTFTs (ms) at each ISL -
prefill_thpt_per_gpu: 1D array of throughput (tokens/s/GPU) at each ISL
Decode Interpolation (selected_decode_interpolation/raw_data.npz):
-
max_kv_tokens: Total KV tokens capacity in decode engine -
x_kv_usage: 1D array of active KV usage percentages [0, 1] -
y_context_length: 1D array of average context lengths tested -
z_itl: 1D array of ITLs (ms) at each (KV usage, context length) point -
z_thpt_per_gpu: 1D array of throughput (tokens/s/GPU) at each point
DGDR Configuration Reference#
This section provides detailed explanations of all DGDR profilingConfig options. The DGDR controller passes this configuration to the profiler script, which is defined in benchmarks/profiler/utils/profiler_argparse.py.
Configuration Structure#
All profiler configuration goes under spec.profilingConfig.config:
apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeploymentRequest metadata: name: my-deployment spec: model: "Qwen/Qwen3-0.6B" # High-level: model to deploy backend: vllm # High-level: inference backend
profilingConfig: profilerImage: "nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.6.1" # Required configMapRef: # Optional: base DGD config name: my-config key: disagg.yaml
config: # Profiler configuration sla: { ... } hardware: { ... } sweep: { ... } aic: { ... } planner: { ... }
deploymentOverrides: # Optional workersImage: "nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.6.1"
SLA Configuration (Required)#
Define your performance requirements and workload characteristics:
profilingConfig: config: sla: isl: 3000 # Average input sequence length (tokens) osl: 150 # Average output sequence length (tokens) ttft: 200.0 # Target Time To First Token (milliseconds) itl: 20.0 # Target Inter-Token Latency (milliseconds)
What these control:
-
ISL/OSL: Based on your expected traffic patterns
-
TTFT: First token latency target (lower = more GPUs needed, affects prefill engine)
-
ITL: Token generation latency target (lower = more GPUs needed, affects decode engine)
-
Trade-offs: Tighter SLAs require more GPU resources
Hardware Configuration (Optional)#
Control GPU search space and constraints:
profilingConfig: config: hardware: min_num_gpus_per_engine: 2 # if not provided, will automatically determine based on model and VRAM size max_num_gpus_per_engine: 8 # Maximum GPUs to test num_gpus_per_node: 8 # GPUs per node (for multi-node MoE) gpu_type: h200_sxm # GPU type hint
When to use:
-
min_num_gpus_per_engine: Skip small TP sizes if your model is large
-
max_num_gpus_per_engine: Limit search space or work around constraints (e.g., AIC attention heads)
-
num_gpus_per_node: Required for MoE models with TEP/DEP sizing
-
gpu_type: Informational, auto-detected by controller
Tip
If you don’t specify hardware constraints, the controller auto-detects based on your model size and available cluster resources.
Sweep Configuration (Optional)#
Control profiling behavior:
profilingConfig: config: sweep: use_ai_configurator: false # Use offline profiling (default: false) prefill_interpolation_granularity: 16 # Samples for prefill TTFT curve decode_interpolation_granularity: 6 # Samples for decode ITL curve
Use cases:
-
use_ai_configurator: Set to
truefor 20-30 second profiling (TensorRT-LLM only) -
prefill_interpolation_granularity: How many samples to benchmark for prefill TTFT curve (lower = faster but may be less accurate)
-
decode_interpolation_granularity: How many samples to benchmark for decode ITL curve (lower = faster but may be less accurate). Since ITL interpolation is a 3d plot and takes longer to run, we default to a smaller number of samples. Increasing this value might quadratically increase the profiling time.
AI Configurator Configuration (Required if use_ai_configurator: true)#
Configure AI Configurator profiling mode:
profilingConfig: config: sweep: use_ai_configurator: true aic_system: h200_sxm # GPU system: h100_sxm, h200_sxm, b200_sxm, gb200_sxm, a100_sxm aic_model_name: QWEN3_32B # AIC model identifier (see supported list) aic_backend_version: "0.20.0" # TensorRT-LLM version: 0.20.0, 1.0.0rc3, 1.0.0rc6
Supported configurations: See AI Configurator documentation
Model name mapping examples:
-
Qwen/Qwen3-32B→QWEN3_32B -
meta-llama/Llama-3.1-70B→LLAMA3.1_70B -
deepseek-ai/DeepSeek-V3→DEEPSEEK_V3
Planner Configuration (Optional)#
Pass arguments to the SLA planner:
profilingConfig: config: planner: planner_min_endpoint: 2 # Minimum endpoints to maintain planner_adjustment_interval: 60 # Adjustment interval (seconds) planner_load_predictor: linear # Load prediction method
Note
Planner arguments use planner_ prefix. See planner documentation for full list.
Engine Configuration (Auto-configured)#
The controller automatically sets these from high-level fields:
You specify:
spec: model: "Qwen/Qwen3-0.6B" backend: vllm
Controller auto-injects into config:
profilingConfig: config: deployment: model: "Qwen/Qwen3-0.6B" # From spec.model engine: backend: vllm # From spec.backend config: /path/to/configmap # From spec.profilingConfig.configMapRef (if provided)
You should not manually setdeployment.model or engine.backend in profilingConfig.config - they are automatically injected from the high-level fields.
Complete Example: AIPerf on Real Engines#
apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeploymentRequest metadata: name: vllm-dense-online spec: model: "Qwen/Qwen3-0.6B" backend: vllm
profilingConfig: profilerImage: "nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.6.1" config: sla: isl: 3000 osl: 150 ttft: 200.0 itl: 20.0
hardware: min_num_gpus_per_engine: 1 max_num_gpus_per_engine: 8
sweep: use_ai_configurator: false
deploymentOverrides: workersImage: "nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.6.1"
autoApply: true
Complete Example: AI Configurator Simulation#
apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeploymentRequest metadata: name: trtllm-aic-offline spec: model: "Qwen/Qwen3-32B" backend: trtllm
profilingConfig: profilerImage: "nvcr.io/nvidia/ai-dynamo/trtllm-runtime:0.6.1" config: sla: isl: 4000 osl: 500 ttft: 300.0 itl: 10.0
sweep: use_ai_configurator: true
aic: system: h200_sxm model_name: QWEN3_32B backend_version: "0.20.0"
deploymentOverrides: workersImage: "nvcr.io/nvidia/ai-dynamo/trtllm-runtime:0.6.1"
autoApply: true
Complete Example: MoE Model#
apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeploymentRequest metadata: name: sglang-moe spec: model: "deepseek-ai/DeepSeek-R1" backend: sglang
profilingConfig: profilerImage: "nvcr.io/nvidia/ai-dynamo/sglang-runtime:0.6.1" config: sla: isl: 2048 osl: 512 ttft: 300.0 itl: 25.0
hardware: num_gpus_per_node: 8 max_num_gpus_per_engine: 32
engine: is_moe_model: true # Enable MoE profiling mode
deploymentOverrides: workersImage: "nvcr.io/nvidia/ai-dynamo/sglang-runtime:0.6.1"
autoApply: true
Troubleshooting#
Profiling Takes Too Long#
Solution 1: Use AI Configurator for rapid profiling (TensorRT-LLM only):
sweep: use_ai_configurator: true
Solution 2: Reduce search space:
config: sweep: min_num_gpus: 4 # Skip TP1, TP2 max_num_gpus: 8 # Don't test beyond TP8
SLA Cannot Be Met#
Symptoms: Profiler reports no configuration meets targets
Solutions:
-
Relax SLA targets (increase TTFT/ITL)
-
Add more GPU resources
-
Try a different backend
-
Use a smaller model
AI Configurator: Attention Head Constraint Error#
Symptoms: Profiling fails with error:
AssertionError: num_heads <N> should be divisible by tp_size <M> and the division result should be >= 4
Cause: AI Configurator requires ≥4 attention heads per GPU. Small models with few heads cannot use high TP sizes.
Affected Models:
-
Qwen3-0.6B (16 heads): Max TP = 4 ❌ Fails at TP=8
-
GPT-2 (12 heads): Max TP = 3
-
Most models <1B parameters: May hit this constraint
Solution: Limit max_num_gpus_per_engine in your DGDR:
profilingConfig: profilerImage: "nvcr.io/nvidia/ai-dynamo/trtllm-runtime:0.6.1" config: hardware: max_num_gpus_per_engine: 4 # For Qwen3-0.6B (16 heads / 4 = max TP of 4) sweep: use_ai_configurator: true aic: system: h200_sxm model_name: QWEN3_0_6B
Calculate Max TP: max_tp = num_attention_heads / 4
Note: This is an AI Configurator limitation. Online profiling doesn’t have this constraint.
Image Pull Errors#
Symptoms: ErrImagePull or ImagePullBackOff
Solution: Ensure image pull secrets are configured:
kubectl create secret docker-registry nvcr-imagepullsecret
--docker-server=nvcr.io
--docker-username='$oauthtoken'
--docker-password=<NGC_API_KEY>
--namespace <your-namespace>
Out of Memory During Profiling#
Symptoms: OOM errors in profiling jobs
Solutions:
-
Reduce
gpu_memory_utilizationin engine config -
Reduce
--max-context-length -
Skip larger TP configurations
-
Use fewer GPUs per test
Unsupported Parallelization Mapping in Backend#
Symptoms: Starttime/runtime error in the backend. For example, prime number of attention heads restrain TP size to be 1 (i.e., falcon-7b with 71 attention heads). Or some backend does not support different TP sizes for prefill and decode.
Solutions:
-
Contact the backend to add support for the use cases and bump backend version in dynamo.
-
Restrain the max and min number of GPUs per engine to the supported range.
Next Steps#
-
Deploy with DGDR: See Quick Start Guide
-
Understand SLA Planner: Read SLA Planner Deep Dive
-
Monitor Deployments: Set up Observability
-
Optimize Performance: See Performance Tuning
Links/Buttons: